학교에 다니던 시절을 떠올려 봅시다.
학창 시절, 우리들은 열심히 공부하고, 잘 공부했는지 시험을 보곤 했습니다. 시험 결과에 따라서, 내가 공부를 잘했는지 확인할 수 있고, 공부 방법도 맞는지 확인할 수 있었습니다. 시험의 종류도 무척 다양했는데요. 입학시험, 중간고사, 기말고사, 쪽지 시험, 수행평가 등 여러 종류의 시험을 통해 학업 성취도를 평가하곤 했습니다. 이렇게 다양한 시험을 진행하고, 평가 방법을 떠올리기 위해, 선생님들은 고민을 많이 했었을 것입니다.
인공지능을 평가하는 방법
인공지능(AI), 즉 머신러닝(Machine Learning, ML)은 데이터를 기반으로 예측 및 의사 결정을 내리는 강력한 도구입니다. 그러나 머신러닝 모델의 예측을 신뢰하기 전에 성능을 평가하여 데이터에서 얼마나 잘 학습했는지 반드시 확인해야 합니다.
그렇다면, 인공지능의 성능은 어떻게 평가할 수 있을까요?
머신러닝 모델의 성능을 평가하는 방법에는 여러 가지가 있으며 가장 일반적인 방법은 다음과 같습니다.
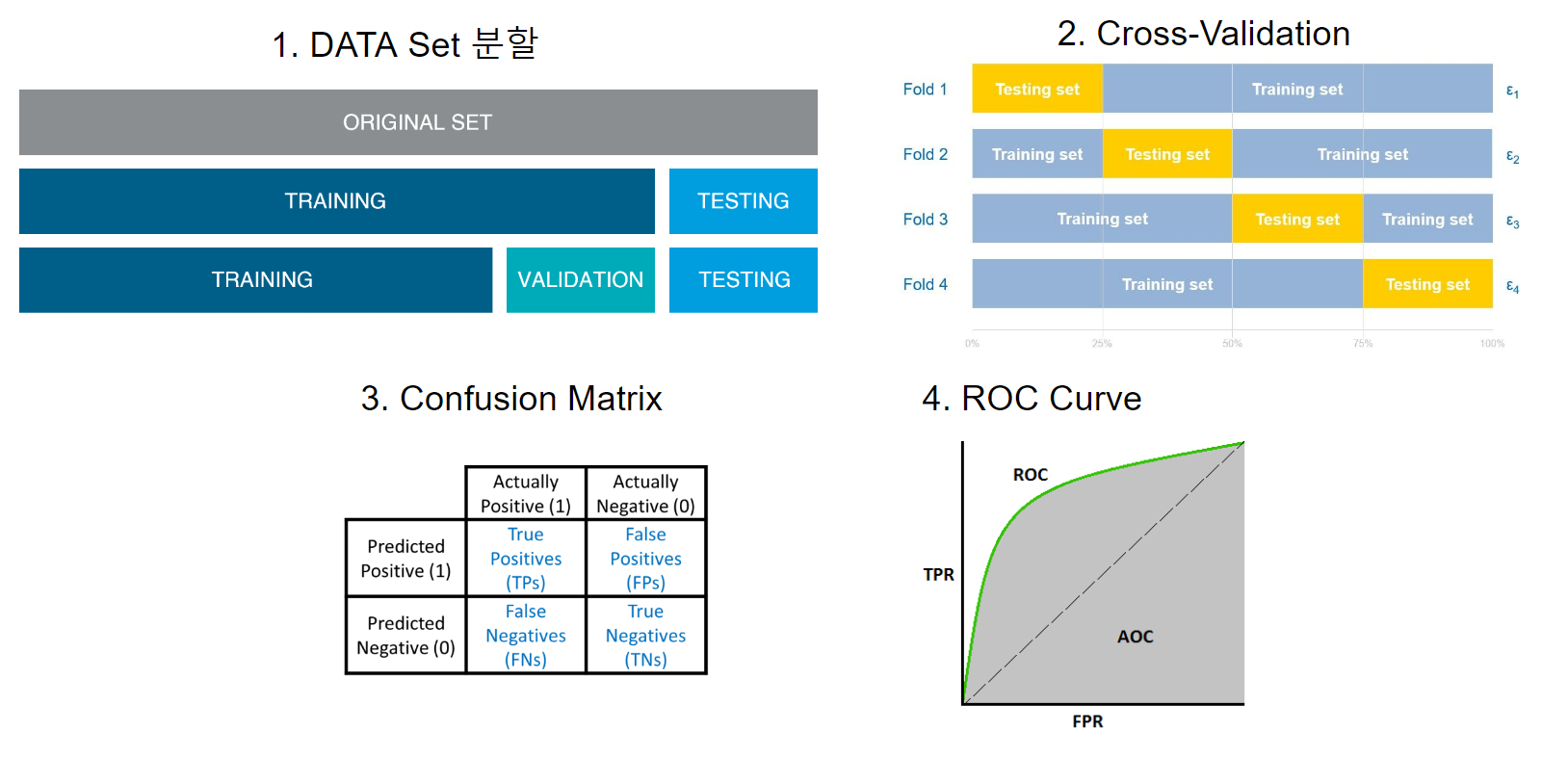
1. 데이터를 Training Set와 Test Set로 분할 : 여기에는 데이터를 두 Set로 나누는 작업이 포함됩니다. 하나는 모델 학습용이고 다른 하나는 Test 용입니다. 모델은 먼저 Training Set에서 학습된 다음 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 및 F1 Score와 같은 평가 지표를 사용하여 Test Set에서 성능을 평가합니다. 이것은 모델의 성능에 대한 초기 평가를 얻는 간단하고 효과적인 방법입니다. Validation Set까지 추가로 분할하여 Training Set로 만들어진 모델의 성능을 측정하기도 합니다. 보통 어떤 모델이 데이터에 적합한지 찾기 위해서 사용됩니다. 이런 경우 일반적으로 Training Set : Validation Set : Test Set = 6 : 2 : 2로 분할합니다.
2. 교차 검증(Cross-validation) : 이 방법은 데이터를 k개의 folds로 나누는 작업을 포함합니다. 여기서 k-1개의 folds는 훈련에 사용되고 나머지 fold는 테스트에 사용됩니다. 이 과정은 Test Set로 사용되는 다른 fold를 사용하여 매번 k회 반복됩니다. 모든 k번의 테스트들의 평균 성능은 전체 성능 평가 지표로 사용됩니다. 이 방법은 데이터의 잠재적 Bias(편향) 또는 변동을 설명하므로 모델 성능에 대해 강력한 평가를 진행할 수 있습니다.
3. Confusion matrix : 이것은 분류(Classification) 모델의 성능을 요약한 표로, True Positive, False Positive, True negative 및 False negative 예측의 수를 보여줍니다. Confusion matrix에서 파생된 지표에는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 및 F1 Score가 포함됩니다. 이 방법은 모델 성능에 대한 자세한 분석을 제공하고, 데이터의 불균형 또는 잘못된 예측과 같은 문제를 찾아낼 때, 도움이 됩니다.
4. ROC Curve : ROC는 Receiver Operating Characteristic의 약자로, ROC Curve는 다양한 분류 임계값에서 이진 분류 모델에 대한 True Positive Rate와 False Positive Rate 사이의 관계를 보여주는 도구입니다. ROC 곡선 아래 영역(AUC)은 이진 분류 모델의 성능을 평가하기 위한 일반적인 평가방법입니다. 이 방법은 특히 불균형 클래스를 처리하거나 다양한 신뢰 수준으로 예측을 수행할 때 모델의 성능에 대한 보다 미묘한 평가를 제공합니다.
5. 평균 제곱 오차(MSE) 및 평균 절대 오차(MAE) : 회귀(Regression) 모델의 성능을 평가하기 위해 일반적으로 사용되는 평가 방법입니다. MSE는 예측된 목표값과 실제 목표값 사이의 평균 제곱 차이이고, MAE는 예측된 목표값과 실제 목표값 사이의 평균 절대 차이입니다. 이러한 평가 지표는 정확한 예측을 수행하는 모델의 기능을 평가하고 예측이 실제 값과 얼마나 다른지 측정하는 데 도움이 됩니다.
6. Log Loss : 확률 기반 분류(Classification) 모델의 성능을 평가하는 데 사용되는 평가 방법입니다. 예측 확률과 실제 클래스 레이블 간의 차이를 측정합니다. Log Loss가 낮을수록 모델의 성능이 좋다고 할 수 있습니다. 이 방법은 의료 진단 또는 사기 탐지와 같은 특정 응용 프로그램에 유용할 수 있는 정확한 확률 추정을 수행하는 모델의 기능을 평가하는 데 도움이 됩니다.
어떤 머신러닝 평가 방법을 선택해야할까?
앞에서 소개한 머신러닝을 평가하는 방법에 6가지가 있었습니다.
물론 이것들은 일반적인 방법이고, 이보다 더 다양한 평가 방법들이 존재할 것입니다. 수 많은 방법을 모두 적용할 수는 없을 텐데, 머신러닝에 적합한 평가 방법을 어떻게 선택할 수 있을지 알아보겠습니다.
- Business 목표 : 평가 지표를 모델의 비즈니스 목표에 맞추는 것이 중요합니다. 예를 들어, 모델의 목표가 사기 탐지 시스템에서 거짓 부정을 최소화하는 것이라면 정확도(Accuracy)보다 정밀도(Precision)가 더 중요한 평가 지표일 수 있습니다.
- 데이터 분포 : 평가 방식은 데이터 분포의 영향을 받을 수 있습니다. 예를 들어, 데이터가 매우 불균형한 경우(예: 적은 수의 긍정적 사례와 많은 수의 부정적 사례) 정확도(Accuracy)는 적절한 평가 지표가 아닐 수 있습니다. 이러한 경우 정밀도(Precision), 재현율(Recall) 또는 F1 Score와 같은 평가 지표가 더 적절할 수 있습니다.
- 모델 복잡성(Complexity) : 모델의 성능은 복잡성에 의해 영향을 받을 수 있습니다. 너무 복잡한 모델은 데이터에 과적합(Overfitting) 되어 일반화 성능이 낮을 수 있고, 너무 단순한 모델은 데이터에 과소적합(Underfitting) 되어 Training Set에서 성능이 낮을 수 있습니다. 데이터에 적합한 모델 복잡도를 선택하고 복잡도가 다른 여러 모델의 성능을 평가하여 최적의 적합도를 결정하는 것이 중요합니다.
- Feature 선택 : 모델에 대한 입력으로 사용되는 Feature는 성능에 상당한 영향을 미칠 수 있습니다. 노이즈가 있거나 관련이 없는 Feature는 모델의 성능을 저하시킬 수 있는 반면 관련 Feature를 추가하면 성능이 향상될 수 있습니다. 모델에 사용할 Feature 들을 신중하게 고려하고, 다양한 Feature 들의 성능을 평가하여 최적의 Feature Set을 결정하는 것이 중요합니다.
마무리 하며,
기계 학습 모델의 성능을 평가하는 것은 기계 학습 프로세스에서 중요한 단계입니다. 적절한 평가 방법과 평가 지표를 사용하는 것을 통해, 모델이 데이터에서 얼마나 잘 학습했는지 확인하고, 잠재적인 문제를 확인하여 성능을 개선하는 방법에 대해 객관적인 결정을 내릴 수 있습니다.
인공지능이나 머신러닝에 대해서 기초적인 지식을 얻고 싶은 분들은 아래 포스팅을 참고해주세요.
머신러닝(ML)을 모르는 초보자를 위한 가이드
머신러닝 : Beginner's Guide 머신러닝(Machine Learning, ML)은 컴퓨터 과학 및 인공지능(AI) 영역 내에서 빠르게 성장하는 분야입니다. 여기에는 시스템이 데이터로부터 "학습"하고 명시적으로 프로그래밍
dongdoridong.tistory.com
'인공지능(AI)' 카테고리의 다른 글
| 인공지능(AI)의 발전으로 가능해진 자율주행 자동차 (0) | 2023.02.05 |
|---|---|
| 인공지능(AI)으로 주식 시장을 예측할 수 있을까? (0) | 2023.02.04 |
| 머신러닝(ML)을 모르는 초보자를 위한 가이드 (2) | 2023.02.02 |
| 인공지능, 딥러닝, 머신러닝 용어의 차이를 알아보자 (4) | 2023.02.02 |
| chatGPT, 화재의 대화형 인공지능 (0) | 2023.01.31 |




댓글