증권가에서도 관심받는 AI
증권가에서는 프로그램을 사용하여 주식을 사고팔 수 있습니다. 이 프로그램에 대해서, 최근 AI, 머신러닝이 발달하면서 관점이 변화하고 있습니다. 지금까지는 사람이 가격과 수량, 시점을 설정해면, 주가가 조건에 맞는 가격이 되었을 때, 프로그램이 매수, 매도를 실행하는 방식으로 사용되었습니다. 머신러닝을 활용하면서, 사람이 직접 설정해야 하는 가격과 수량, 시점에 대해서도 프로그램이 판단할 수 있게 되었습니다. 사람이 단지, 남들보다 좀 더 빨리, 편하게 주식을 사고팔기 위해서 프로그램을 사용했던 것에서, 더 좋은 가격, 수량, 시점까지 정해주고, 이를 실행하기 위해서 프로그램을 사용하는 것으로 발전한 것입니다.
주가 예측은 수년 동안 금융 기관과 개인 투자자 모두가 관심을 가지고 있지만, 그만큼 어려운 작업입니다. 주식 시장이 시작된 이후 수십 년 동안, 기술 분석 및 기본 분석과 같은 전통적인 재무 분석 기술이 주가 예측에 사용되었지만, 인공 지능(AI) 및 머신 러닝의 발달을 통해, 보다 정교하고 정확한 예측을 위한 새로운 기회를 열었다고 볼 수 있습니다.
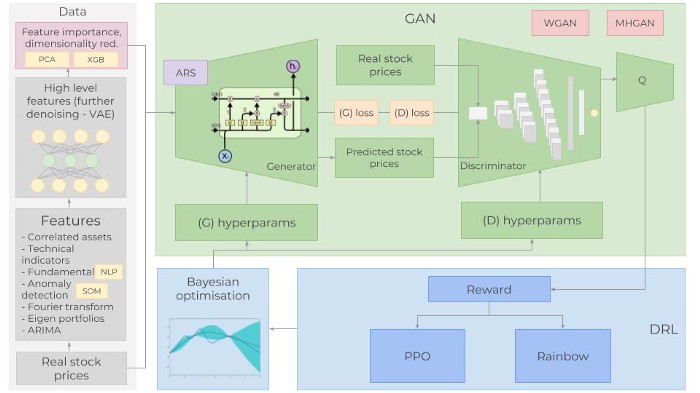
주식 가격을 분석하기 위한 머신러닝 모델의 종류
주식 가격을 분석하고 예측하는 데 사용할 수 있는 몇 가지 머신러닝 알고리즘이 있습니다. 가장 일반적으로 사용되는 접근 방식에는 시계열 분석, 회귀 분석 및 신경망 분석, Random Forest가 있습니다. 시계열 분석은 과거 데이터를 기반으로 미래 값을 모델링하고 예측하는 데 사용됩니다. 회귀 분석은 독립 변수와 주가 간의 관계를 모델링하는 데 사용됩니다. 반면 신경망 분석은 여러 변수 간의 복잡한 비선형 관계를 모델링하는 데 사용됩니다. Random Forest는 Decision Tree를 여러 개 조합하여, 여러 변수 간의 관계를 모델링하기 위해서 사용됩니다.
- 시계열 분석 : 이 유형의 모델은 과거 주식 데이터를 사용하여 미래 주가를 예측합니다. 주식 데이터의 패턴과 추세를 모델링하고 이를 사용하여 미래 가치를 예측합니다. 시계열 분석은 데이터의 역사가 길고 추세가 명확한 주식에 자주 사용됩니다. 주로 LSTM 모델을 사용합니다.
- 회귀(Regression) 분석 : 이 모델은 통계적 접근 방식을 사용하여 경제 지표 및 회사 재무와 같은 독립 변수와 주가 간의 관계를 모델링합니다. 회귀 분석은 독립 변수와 주가 사이에 명확한 관계가 있는 주식에 유용합니다.
- 신경망(Neural Networks) : 신경망은 여러 변수 간의 복잡한 비선형 관계를 모델링하는 데 사용할 수 있는 일종의 머신러닝 모델입니다. 신경망은 주식 데이터와 기타 관련 재무 및 경제 변수 간의 관계를 모델링하여 주식 가격을 예측하는 데 사용할 수 있습니다.
- Random Forest : Random Forest는 주가 예측에 사용할 수 있는 앙상블 머신러닝 알고리즘입니다. 의사 결정 트리 조합을 사용하여 예측을 수행하며 변수 간의 복잡하고 비선형적인 관계를 처리하는 기능으로 알려져 있습니다.
머신러닝으로 주가를 예측하는 과정
AI가 주가를 예측할 수 있도록 만드는 과정은 다른 머신러닝 모델들의 학습 프로세스를 만드는 것과 동일합니다. 다만, 주식이라는 도메인의 특징이 잘 반영될 수 있도록 모델의 선정, 데이터의 전처리, Feature의 선정 등이 중요합니다.
1. 데이터 준비 및 Feature 선정 : 머신러닝 알고리즘을 적용하여 주가를 예측하기 전에 데이터를 준비하고 정리하는 것이 중요합니다. 여기에는 누락된 값 제거, 이상값 처리, 머신러닝 알고리즘에서 사용할 수 있는 형식으로 데이터 변환이 포함됩니다. 데이터 준비 외에도 Feature 선정은 주가 예측 프로세스에서 매우 중요한 단계입니다. 여기에는 주가 움직임에 대한 주요 통찰력을 제공할 수 있는 이동 평균 및 거래량, 전날 주가 변화량과 같은 기존 데이터 중에서 Feature을 선택하는 것이 될 수 있습니다.
2. 모델 Training 및 검증 : 데이터가 준비되고 Feature 선정을 했다면, 다음 단계는 머신러닝 모델을 학습시키는 것입니다. 여기에는 데이터를 Training Set와 Test Set로 분할하여, Training Set로 모델을 학습시키고, Test Set로 성능을 평가하는 작업이 포함됩니다. Cross-validation과 같은 평가 방법이 데이터의 여러 하위 집합에 대한 성능을 평가하여 모델의 정확도를 개선하는 데에도 사용할 수 있습니다.
정리하며,
최근 주가 예측을 위해 개발된 머신러닝 프로그램이 많이 있습니다. 이러한 프로그램은 시계열 분석, 회귀 분석 및 신경망을 포함한 다양한 머신러닝 알고리즘을 사용하여 주가를 예측합니다. 이러한 알고리즘은 과거 주식 데이터뿐만 아니라 기타 관련 재무 및 경제 변수에 대해 학습되어, 향후 주가 변동을 예측할 수 있는 모델을 구축할 수 있습니다.
AI와 머신러닝으로 주가를 예측하는 것은 데이터 준비, Feature 선정 및 모델 Training의 조합이 필요한 복잡한 작업입니다. 그러나 이러한 단계를 따르면 금융 기관과 개인 투자자는 AI 및 머신러닝의 힘을 활용하여 주식 투자에 대해 더 많은 정보를 바탕으로 판단하여, 결정을 내릴 수 있습니다.
'인공지능(AI)' 카테고리의 다른 글
| DALL·E 2, 완벽한 화가로 변신한 인공지능(AI) (1) | 2023.02.06 |
|---|---|
| 인공지능(AI)의 발전으로 가능해진 자율주행 자동차 (0) | 2023.02.05 |
| 인공지능(AI)은 성능은 어떻게 평가할 수 있을까? (1) | 2023.02.03 |
| 머신러닝(ML)을 모르는 초보자를 위한 가이드 (2) | 2023.02.02 |
| 인공지능, 딥러닝, 머신러닝 용어의 차이를 알아보자 (4) | 2023.02.02 |




댓글