강화학습은 채찍과 당근이 필요한 인공지능
머신러닝(Machine Learning)은 알고리즘을 사용하여 데이터를 분석하고 학습하는 일종의 인공지능(AI)입니다. 머신러닝을 진행하는 유형에 따라서, 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning, RL)의 3가지로 나눌 수 있습니다. 따라서, 강화학습은 머신러닝의 한 부분이라고 할 수 있습니다.
강화학습은 현재 상태에서, 어떤 행동을 하는 것이 좋을지 방향을 찾는 학습 방법이라고 할 수 있습니다. 학습 방향을 결정짓기 위해서, 행동할 때마다 보상(Reward)이 주어지게 됩니다. 결과적으로, 강화학습은 행동에 대한 보상을 극대화하기 위해 어떤 행동을 할지 방향을 찾는 학습이라고 할 수 있습니다.
이런 강화학습의 특성 때문에, 지도 및 비지도 학습과는 다르게 정적 Data Set으로부터 학습하는 것이 아니라, 보다 역동적인 환경에서 행동하며 수집된 보상에 대한 경험으로부터 학습합니다. 그러다 보니, 지도 및 비지도 학습에서 필요한, 학습 데이터 수집, 데이터 전처리, Lable 지정 과정이 필요 없습니다. 강화학습은 환경과의 상호작용을 통해 학습을 하는 머신러닝 방법인 것이죠. 따라서, 적절한 보상이 주어지는 환경이 갖춰진다면, 강화학습 모델은 사람이 개입하지 않고도, 더 나은 결과를 위한 학습을 스스로 진행한다는 것을 알 수 있습니다.
참고로, 딥러닝(Deep Learning)은 특정 Pattern을 찾기 위한 알고리즘을 학습시키기 위해 사용되는 방법입니다. 딥러닝은 학습 데이터로부터 학습한 뒤, 새로운 데이터에 학습한 내용을 적용시키는 반면, 강화학습은 보상을 최대화하기 위한 방향으로 학습하며, 행동을 조정하는 방법으로 차이가 있습니다. 하지만, 강화학습과 딥러닝의 관계는 상호 배타적이지 않고, 상호작용이 가능한 관계라고 볼 수 있습니다. 복잡한 강화학습 문제에서는 딥러닝의 신경망(Neural Networks)을 이용하여, Deep Reinforcement Learning이 사용되기도 합니다. 딥러닝에 관한 내용은 아래 포스팅을 참고하셔도 좋습니다.
딥러닝, 누구나 만들 수 있는 인공지능(AI) 기술
딥러닝, 누구나 만들 수 있는 인공지능(AI) 기술
딥러닝 붐의 시작 2016년, 구글 딥마인드(DeepMind)의 알파고(Alphago)와 이세돌 9단의 대국으로 화제가 되었습니다. 그 뒤로, 딥러닝(Deep Learning)이라는 인공지능(AI)의 분야는 전 세계 사람들의 큰 관심
dongdoridong.tistory.com
강화학습의 원리
강화학습은 행동에 대한 보상을 극대화하기 위해, 수많은 시행착오를 거쳐 어떤 행동을 할지 방향을 찾는 학습입니다. 이 과정이 어떻게 일어나는 것인지 게임하는 상황을 통해서 확인해 보겠습니다.
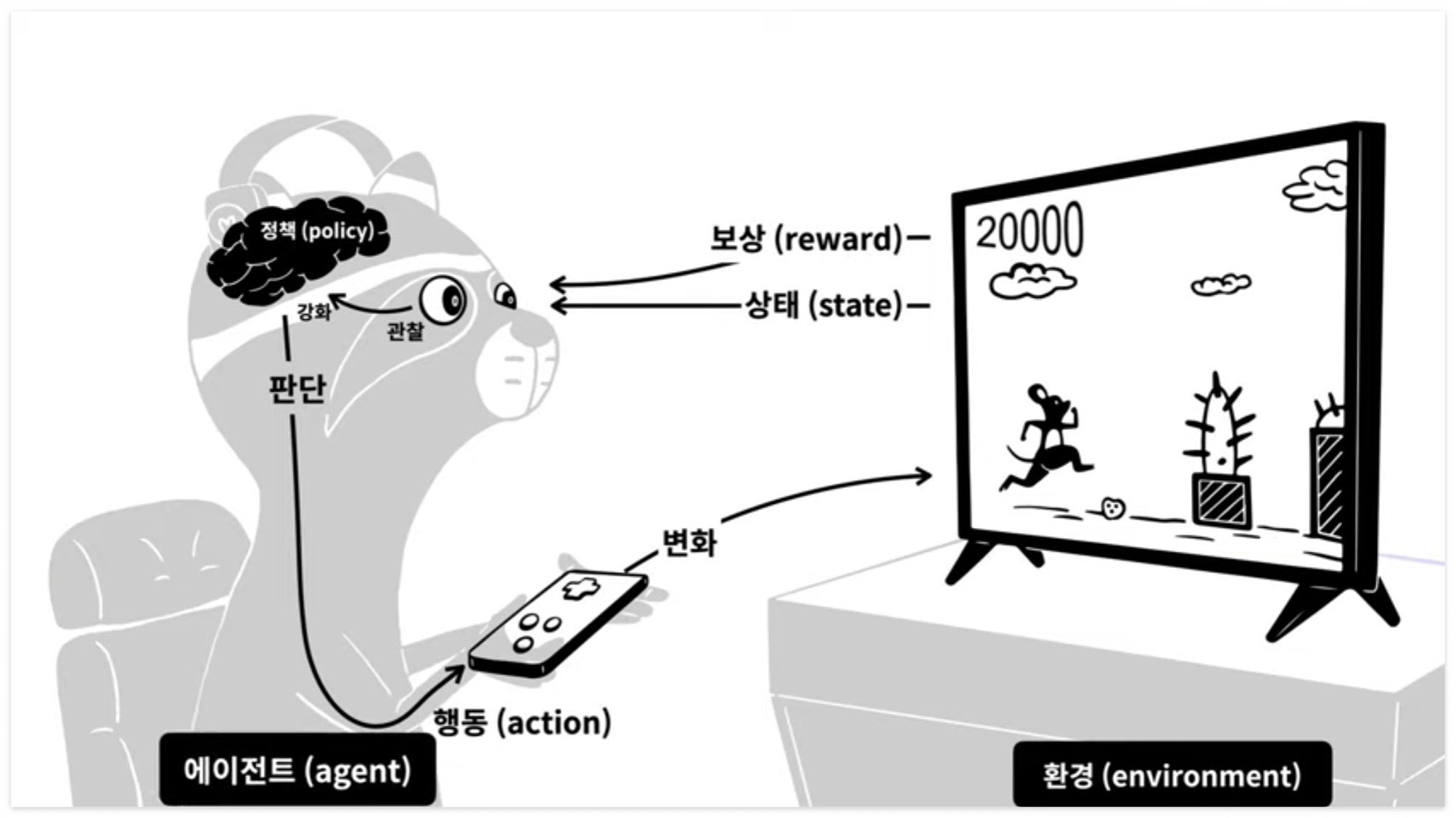
우리가 장애물을 피하는 게임을 한다고 해봅시다. 게임 내의 캐릭터 위치, 장애물 위치, 움직이는 속도 등 게임의 상태가 있습니다. 그리고 장애물을 피할 때마다 올라가는 점수가 있습니다. 게이머는 게임 속의 상태에 따른 점수를 보고, 어떤 조작을 할지 판단하고, 행동에 옮기게 됩니다. 여러 번의 시행착오를 거치게 되면, 게이머는 점수를 크게 얻을 수 있는 방향으로 판단을 내리고, 조작을 하게 됩니다. 결과적으로 장애물을 피하는 게임에서 많은 점수를 얻을 수 있도록 판단할 수 있는 판단력이 길러지게 되는 것입니다.
이 과정을 강화학습으로 비유해 보도록 하겠습니다. 게이머는 Agent가 되고, 게임은 환경(Environment)이라고 볼 수 있습니다. 게임이 많은 점수를 얻을 수 있도록 판단하는 것이 목표라면, 강화학습은 환경 내에서 일어나는 여러 가지 상태(State)에 따라서, 더 많은 보상(Reward)을 받을 수 있는 행동(Action)을 할 수 있는 정책(Policy)을 만드는 것이 목표라고 할 수 있습니다. 다시 말해, Agent, Environment, Reward가 제대로 정의할 수 있다면, 강화학습으로 해결이 가능하다고 볼 수 있습니다.
강화학습이 더 많은 보상을 받기 위한 행동을 찾기 위해서 가지고 있는 2가지 대표적인 특징이 있습니다. 이 특징들은 지도 및 비지도 학습에서는 볼 수 없는 독특한 특징입니다.
- Trial & Error (시행착오) : 강화학습은 처음에는 어떤 행동을 해야 하는지 전혀 알지 못하는 상태에서 시작하게 됩니다. 수많은 시도와 실패를 통해서, 보상을 최대화할 수 있도록 학습을 하게 되고, 이를 달성할 수 있는 행동을 찾게 됩니다.
- Delayed Reward (지연된 보상) : 보상을 최대화하는 방향으로 학습이 진행되지만, 보상 자체는 행동을 취한 즉시 주어지지 않을 수 있다는 특징입니다. 예를 들어, 체스나 바둑과 같은 게임에서, 당장의 이익을 취할 수는 있지만, 결과적으로 게임 자체의 승리로 이어지지는 않을 수도 있다는 것입니다. 따라서, 지연된 보상까지 포함한 총 보상 값의 합이 최대화가 되도록 행동을 선택해야 합니다.
강화학습 사례
강화학습의 대표적인 사례로는 알파고(Alphago)가 있습니다. 알파고는 바둑을 학습하기 위해, 먼저 사람의 바둑 경기 Data를 바탕으로 학습을 했습니다. 이를 통해, Deep Neural Networks 기반의 보상 체계를 먼저 확립할 수 있었습니다. 이후에는 스스로 수많은 경기를 치르면서, 보상 체계를 업데이트하고, 승리할 수 있는 행동에 대해 학습을 했습니다. 즉, 승리에 대해 보상을 주면서, 승리를 위한 행동이 어떤 것인지 학습한 것입니다.
추가로, 자율주행 기술에도 PBT(Population based Training), 심층 강화학습 등을 적용하여 모델을 만드는 기업들이 여럿 등장하고 있습니다. 또한 단백질 분석 및 예측에 대해서 학습하여, 바이오와 신소재 분야에서 강화학습이 적용되는 사례도 있다고 합니다. 바둑과 체스 외의 여러 가지 게임에도 강화학습이 적용되면서, 인간의 기록을 뛰어넘는 AI 프로그램들이 속속히 나오고 있습니다.
아래 영상은 강화학습 알고리즘으로 걸음을 익히는 과정을 보여주는 사례로, 강화학습의 특징과 원리를 잘 보여주는 사례라고 할 수 있습니다.
https://youtu.be/eVccQ82BekI
'인공지능(AI)' 카테고리의 다른 글
| [세미나 리뷰] From Model-centric To Data-centric AI (2) (0) | 2023.02.10 |
|---|---|
| [세미나 리뷰] From Model-centric To Data-centric AI (1) (0) | 2023.02.09 |
| 딥러닝, 누구나 만들 수 있는 인공지능(AI) 기술 (2) | 2023.02.07 |
| DALL·E 2, 완벽한 화가로 변신한 인공지능(AI) (1) | 2023.02.06 |
| 인공지능(AI)의 발전으로 가능해진 자율주행 자동차 (0) | 2023.02.05 |




댓글