Introduction
빅데이터(Big Data)는 이미 널리 사용되고 있는 용어라 많은 분들이 익숙하실 겁니다. 정확한 유래에 대해선 아직도 논란이 분분하지만, 가장 유력한 설은 1990년대 인터넷 이용이 확대되면서, 점차 강력한 컴퓨팅 기술이 필요하게 되었고, 1997년 7월 NASA 과학자들의 논문(Application-Controlled Demand Paging for Out-of-Core Visualization)에 컴퓨터의 메모리나 디스크의 성능에 부담을 주는 것을 'Big Data Problem'이라고 부르면서, '빅데이터'라는 용어가 처음으로 등장하게 되었다고 합니다. 이후, 20~30년 동안 빅데이터를 다루는 기술들은 매우 빠른 속도로 발전했고, 현재는 다양한 ML/DL 모델들을 활용하여 AI System을 적용하기까지 이르렀습니다.
데이터 분석과 모델 개발 과정에서는 성능 개선을 위한 고민에 빠지게 됩니다. 점점 더 발전된 방법론들이 개발/연구되고, 세상에 공개되어서 그런지, 대부분의 경우, 성능 개선 고민을 모델에 집중하게 됩니다. 최근 AI 연구도 모델로 쏠리고 있는데요. 오늘은 이와 관련해 모델보다 데이터에 집중하는 것이 더 중요하다는 한 세미나를 리뷰해보고자 합니다. 바로 2021년 3월 25일에 진행된 앤드류 응(Andrew Ng) 교수의 "A Chat with Andrew on MLOps : From Model-centric To Data-centric AI"입니다.
Data is Food for AI
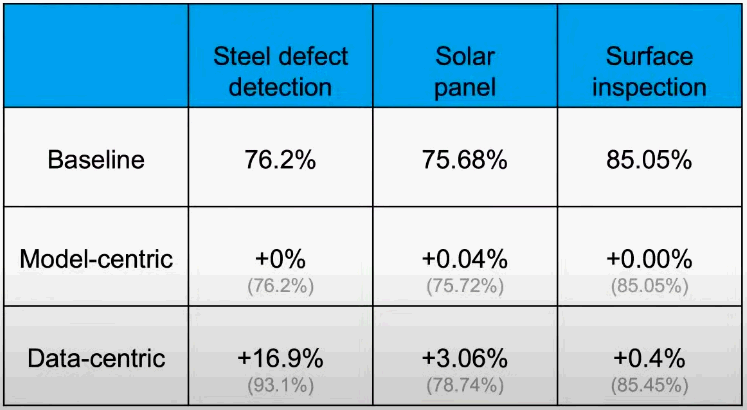
AI System은 Code와 Data로 이루어져 있습니다. 많은 사람이 Code를 개선하기 위해 Model과 Algorithm에 집중하고 있지만, 실질적으로 AI System의 성능을 높이는 것은 Code의 개선이 아니라 Data의 개선이라고 말합니다. 양질의 Data를 잘 갖추는 것이 성능개선에 더 효과적이라는 것입니다. 아래 표를 보시면, 실제로 몇 가지 Case를 통해 Data의 개선이 더 효과적임을 보여줍니다.
AI System의 학습 과정은 요리 과정과 비슷합니다. 좋은 품질의 식재료를 준비하는 과정과 Data를 준비하는 과정, 요리하는 과정과 Model을 훈련시키는 과정을 서로 유사한 단계라고 볼 수 있습니다. 요리에서 신선하고 좋은 퀄리티의 식재료 준비가 더 오래 걸리고 중요하듯, AI System에서도 좋은 Data를 준비하는 과정이 훨씬 더 오래 걸린다고 합니다. 다시 말해, Data 준비의 비중이 훨씬 크지만, 앞서 언급한 것처럼, 현재 AI 연구의 99%는 Action, 즉 Model에 치중되어 있습니다.
Labeling Consistency of an ML Project
그렇다면, 어떤 Data가 High Quality Data일까요? 모든 Data에서 품질에 대해 일관된 기준(Consistency)을 갖는 것이 중요하다고 합니다. 특히 Labeling에 있어, 서로 다른 기준을 적용하면, 일관성이 떨어져 Data Quality에 큰 악영향을 미칩니다. 예를 들어 음성인식과 사물 인식 Model을 학습시키기 위한 Data의 경우, 서로 다른 기준의 Labeling을 없애야 합니다. 음성 인식 Data에서 Um과 같은 Filler를 모두 없애거나, Model이 스스로 학습할 수 있도록 모두 두어야 한다고 합니다. 즉, Data가 일관적이어야 Model이 성공적으로 Data를 학습할 수 있는 것입니다. 사물 인식 Model에서의 Labeling 과정을 보면, 어떤 이미지에서는 사물의 전체 모습이 있고, 어떤 이미지에서는 사물의 일부 모습만 있을 때, Labeling의 기준이 다르게 되고, Model의 성능이 떨어지게 됩니다.

응 교수는 이런 문제를 해결하기 위한 방법으로, 기준을 맞추는 과정을 반복하여 Labeling에서의 일관성을 얻는 것이 필요하다고 말합니다. 아래 3가지 과정을 반복해서 일관된 Data를 얻어야 한다는 것입니다.
- 독립적인 Labler들에게 Data sample을 Labeliong 하도록 요청
- 서로 다르게 LAbeling 한 것을 찾기 위해 Labeler 간에 일치하는 정도를 계산
- 일치하지 않는 LAbeling에 대해서 가이드라인을 수정하고 일관된 Labeling이 얻어질 때까지 반복
Continue
오늘은 앤드류 응(Andrew Ng) 교수의 "A Chat with Andrew on MLOps : From Model-centric To Data-centric AI" 세미나에 대해서 소개 하고, 세미나의 주제를 표현하는 개념에 대해서 알아보았습니다. 다음 포스팅에서는 앤드류 응 교수가 제안하는 MLOps의 개념과 Data의 품질을 높이기 위한 방법에 대해서 살펴보도록 하겠습니다.
'인공지능(AI)' 카테고리의 다른 글
| 10초 만에 감동을 만드는 AI 아티스트 (0) | 2023.02.11 |
|---|---|
| [세미나 리뷰] From Model-centric To Data-centric AI (2) (0) | 2023.02.10 |
| 강화학습, 상벌점 제도를 적용한 인공지능(AI) (1) | 2023.02.08 |
| 딥러닝, 누구나 만들 수 있는 인공지능(AI) 기술 (2) | 2023.02.07 |
| DALL·E 2, 완벽한 화가로 변신한 인공지능(AI) (1) | 2023.02.06 |




댓글