지난 이야기 요약
지난 포스팅에서는 앤드류 응(Andrew Ng) 교수의 "A Chat with Andrew on MLOps : From Model-centric To Data-centric AI" 세미나에 대해서 소개하고, 세미나의 주제를 표현하는 개념에 대해서 알아보았습니다. 많은 사람이 AI System의 성능 개선을 위해서, Code 즉, Model과 Algorithm에 집중하고 있지만, 실질적으로 AI System의 성능을 높이는 것은 Code의 개선이 아니라 Data의 개선이라고 앤드류 응 교수는 주장했습니다. High Quality Data를 만드는 방법 중의 일부로, Labeling에서의 Consistency를 유지하는 것을 소개했습니다. 오늘은 앤드류 응 교수가 제안하는 MLOps의 개념과 Data의 품질을 높이기 위한 방법에 대해서 살펴보도록 하겠습니다.
[세미나 리뷰] From Model-centric To Data-centric AI (1)
[세미나 리뷰] From Model-centric To Data-centric AI (1)
Introduction 빅데이터(Big Data)는 이미 널리 사용되고 있는 용어라 많은 분들이 익숙하실 겁니다. 정확한 유래에 대해선 아직도 논란이 분분하지만, 가장 유력한 설은 1990년대 인터넷 이용이 확대되
dongdoridong.tistory.com
Clean Data vs Noisy Data
이 세미나에서는 Data의 품질을 높이기 위한 방법으로 Data 사이즈와 일관성(Consistency)의 관계에 대해서도 이야기하고 있습니다. 헬리콥터의 입력 Voltage와 Speed의 관계를 학습한 Model을 추론한 결과를 보여주면서, 설명했습니다.
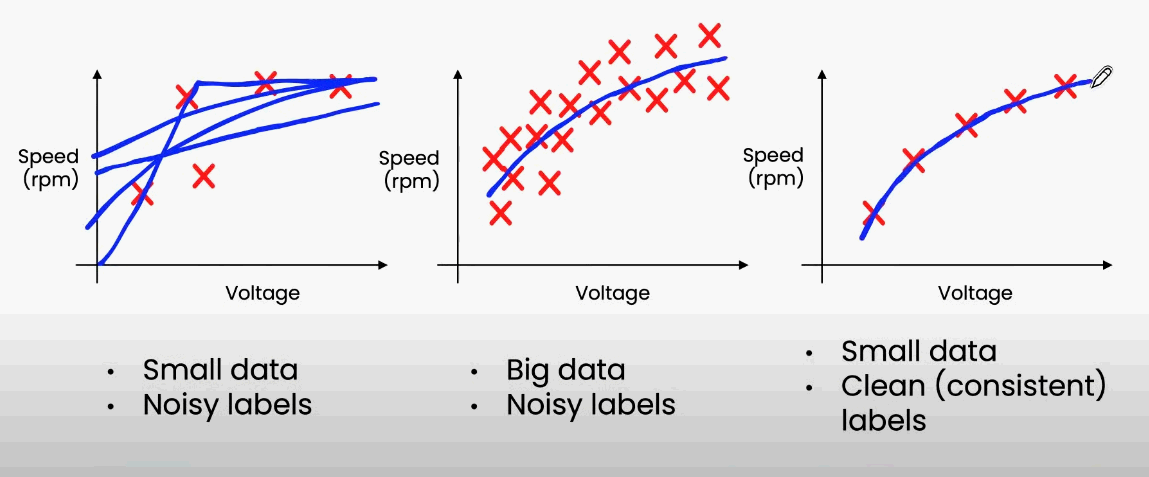
"Small, Noisy" Dataset에서는 정확도가 낮게 측정되고, "Big, Noisy"와 "Small, Clean" Dataset에서는 정확도가 높게 나타납니다. 이 사례의 결과를 요약해 보면, 다음과 같이 정리할 수 있습니다.
- Data가 많으면, Noise가 있어도 Model의 성능이 높을 수 있다.
- Data가 적으면, Label의 Quality가 Model의 성능에 큰 영향을 끼친다.
1번의 경우에는 Data를 더 많이 모아야 하는 것이 정확도를 높이는 방법이고, 2번의 경우에는 Label Quality를 높여야 하는 것이 Model의 정확도를 높이는 방법임을 알 수 있습니다. 그렇다면, "Small, Clean"과 "Big, Noisy" Dataset을 비교한다면, 어떤 Data가 정확도 개선에 더 효율적일까요?

실험해 본 결과, Big Data로 Clean Data의 수준을 따라잡기 위해서는 거의 2~3배의 Data가 필요하다고 합니다. 즉, Data의 Quality를 높이는 것이, Model의 성능 개선에 더 효과적이라는 것을 볼 수 있는 것이죠. 또한 이미 충분히 많은 Data를 사용하고 있는 경우, 무한정으로 Data를 늘릴 수 없으니, Data 관리는 그만큼 더 중요하다는 것을 알 수 있습니다.
MLOps의 등장
앤드류 응 교수는 이러한 배경을 바탕으로 AI System에서 Data 관리의 중요성을 강조합니다. 개발 시기에는 물론, 이후에도 지속적으로 Data를 분석하며, Model을 개선시키는 사이클이 필요하다는 것입니다.
여기서 등장하는 것이 MLOps입니다. MLOps는 DevOps 원칙을 AI/ML에 도입하여 개발(Dev)과 운영(Ops)을 통합하는 것을 목표로 하는 ML 엔지니어링 방식입니다. 단순히 Model 개발뿐만 아니라, Data를 수집하고 분석하는 단계(Data 수집, 분석, Labeling, Validation, 전처리)와 Model을 학습하고 배포하는 단계(Model Training, Validation, Deployment)까지 전 과정을 AI Lifecycle로 보는 것입니다.

마무리하며,
앤드류 응 교수는 세미나에서 MLOps를 통해, AI System Life Cycle의 모든 단계에서 Consistent & High Quality Data를 보장하는 것이 중요하다고 강조합니다. Model보다는 Data 관리로 관점을 바꿔보는 것을 제안하여, 좋은 Data가 많아야 한다고 주장하는 것입니다. 다시 말해, From Model-centric To Data-centric : Big Data to Good Data를 주장하고 있습니다. 마지막으로 응 교수가 말하는 Good Data란 무엇인지 살펴보고, 마무리하겠습니다.
- Defined Consistently
- Cover of important Cased
- Has timely feedback from production data
- Sized appropriately
'인공지능(AI)' 카테고리의 다른 글
| 신경망(Neural Network), AI 학습의 숨은 조력자 (0) | 2023.02.13 |
|---|---|
| 10초 만에 감동을 만드는 AI 아티스트 (0) | 2023.02.11 |
| [세미나 리뷰] From Model-centric To Data-centric AI (1) (0) | 2023.02.09 |
| 강화학습, 상벌점 제도를 적용한 인공지능(AI) (1) | 2023.02.08 |
| 딥러닝, 누구나 만들 수 있는 인공지능(AI) 기술 (2) | 2023.02.07 |




댓글